Case study · Solo · 2025 — présent
SentinelAI — analyse boursière multi-agents.
Plateforme d'analyse boursière qui orchestre 12 agents IA spécialisés — fondamentaux, sentiment, technique, macro — en parallèle. Un orchestrateur synthétise leurs signaux en score pondéré + résumé LLM par ticker.
Meta-ensemble machine learning, backtesting historique, apprentissage autonome de la pondération des agents selon leur performance. Stack Python / FastAPI / Next.js, orchestration OpenAI + Anthropic.
Le problème résolu
L'analyse boursière individuelle souffre d'un biais cognitif bien documenté : l'investisseur privé privilégie un seul angle — souvent l'analyse technique ou le buzz social — et néglige les fondamentaux, la macroéconomie, ou le sentiment global. Les plateformes existantes (TradingView, Seeking Alpha, Koyfin) fournissent des données brutes mais rarement une synthèse multi-angle agrégée.
SentinelAI cherche à résoudre ce problème en orchestrant 12 angles d'analyse simultanément, chacun exécuté par un agent LLM spécialisé avec son propre corpus de prompts, ses outils d'API (Yahoo Finance, Alpha Vantage, FRED, SEC EDGAR, Reddit/Twitter sentiment), et son modèle de scoring.
L'approche multi-agents
Plutôt qu'un seul LLM générique qui "pense à tout", l'architecture repose sur la séparation des préoccupations. Chaque agent a un périmètre étroit :
- Agent fondamentaux — lecture et parsing des 10-K / 10-Q SEC, ratios (P/E, P/B, EV/EBITDA, ROE, endettement).
- Agent sentiment news — scraping headlines, classification NLP (positif/neutre/négatif pondéré par source).
- Agent sentiment social — Reddit (r/wallstreetbets, r/stocks), Twitter/X, StockTwits — détection de mouvements de foule.
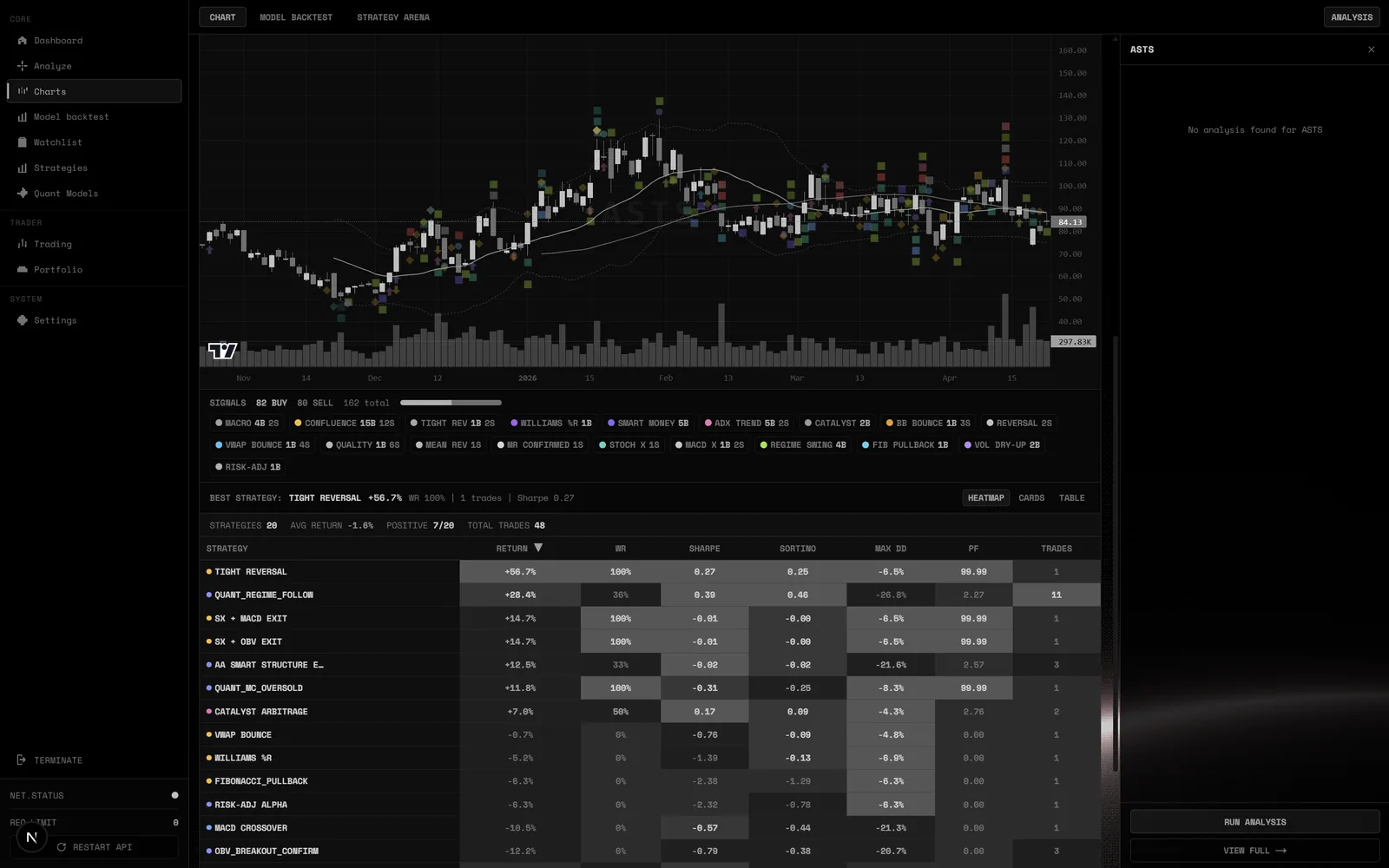
- Agent technique — signaux candlesticks, indicateurs (RSI, MACD, Bollinger), patterns de régression.
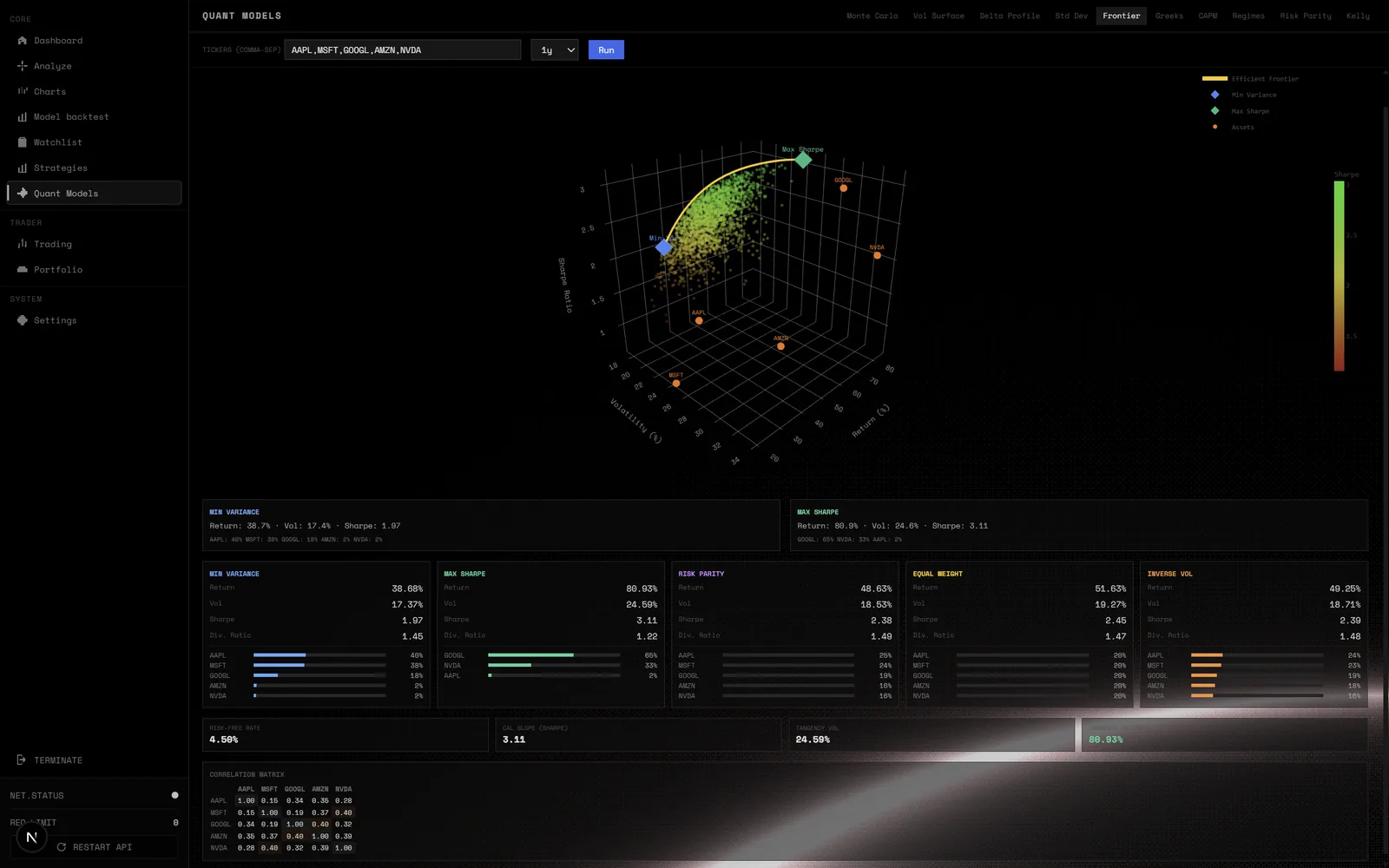
- Agent macro — FRED (taux, inflation, PMI), contexte sectoriel, corrélations inter-marchés.
- Agent insiders — transactions dirigeants (SEC Form 4), concentration de signal.
- Agent options flow — put/call ratio, open interest unusual, anomalies de volume.
- Agent comparables — valorisation relative vs peers sectoriels.
- Agent earnings — historique surprises, guidance management, consensus analystes.
- Agent risques — litiges, régulation, dépendances clients, goodwill.
- Agent géopolitique — événements macro internationaux, sanctions, flux de capitaux.
- Agent ESG — scores ESG, controverses récentes, flux ETF durables.
Chaque agent retourne un score -100 à +100 et un raisonnement justifié citant ses sources. L'orchestrateur (lui-même un LLM) combine ces 12 sorties en pondérant selon la performance historique de chaque agent, puis produit un verdict global + résumé narratif.
Architecture technique
Trois couches :
- Couche de collecte — Python / FastAPI. Scheduler (APScheduler) qui déclenche les 12 agents en parallèle via
asyncio.gather. Chaque agent est une classe avec interface commune (fetch → analyze → score). Résultats bufferisés en Postgres. - Couche d'orchestration — orchestrateur LLM (prompts Anthropic Claude + fallback OpenAI GPT-4o). Lit les 12 scores bufferisés, produit la synthèse. Utilise un cache par ticker pour éviter les recalculs.
- Couche UI — Next.js 14, TypeScript, TailwindCSS. Dashboard temps réel avec streaming des scores via SSE. Graph Recharts pour l'évolution historique.
Déploiement : Docker Compose (API + Postgres + Redis cache) sur VPS, frontend Vercel.
Meta-ensemble ML et apprentissage autonome
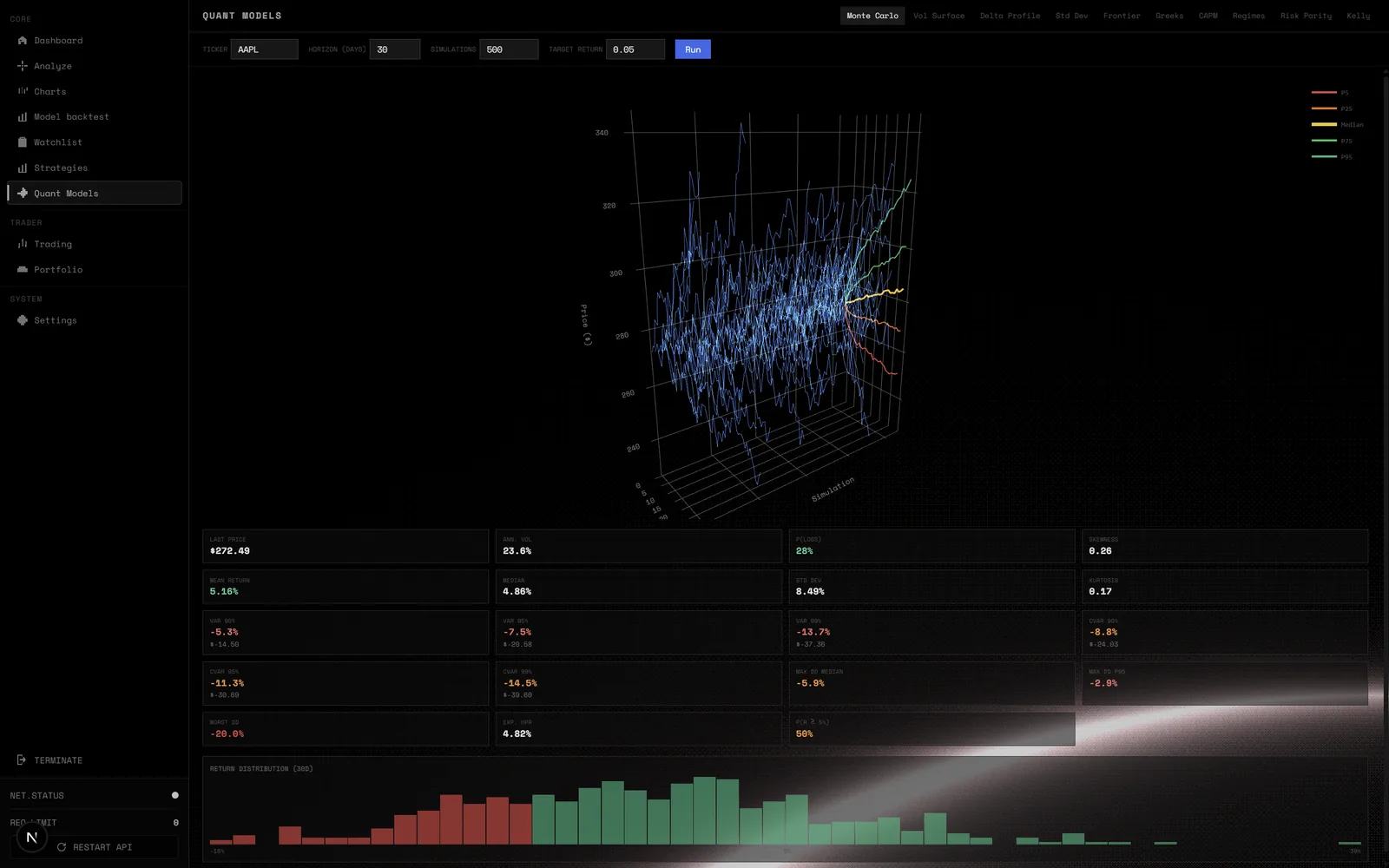
Le point le plus intéressant (et le plus difficile) : les 12 agents n'ont pas la même fiabilité selon les conditions de marché. L'agent sentiment social surperforme en période de spéculation retail (2021), l'agent fondamentaux en bear market (2022). L'orchestrateur ne peut pas les pondérer à la main.
Solution : un meta-modèle (scikit-learn + LightGBM) s'entraîne sur les prédictions historiques des 12 agents vs le rendement réel N+30 jours, et apprend les pondérations optimales par régime de marché. Ce méta-modèle est ré-entraîné chaque semaine sur un rolling window de 2 ans.
Le backtesting tourne sur un dataset de 500 tickers S&P 500 + NASDAQ 100 depuis 2018. Les résultats préliminaires suggèrent un Sharpe ratio supérieur à la stratégie baseline (buy-and-hold SPY), mais c'est en cours de validation sur données out-of-sample.
Défis rencontrés
- Coût LLM — 12 agents × 500 tickers × 1 run/jour = ~250 000 appels API/mois. Arbitrage précision vs coût : certains agents tournent sur Haiku 4.5 (cheap), d'autres sur Opus 4.7 (précis mais 10× plus cher).
- Latence —
asyncio.gatherbornée par l'agent le plus lent (sentiment social, souvent). Ajout d'un timeout + fallback sur cache récent. - Biais de survivance — le backtesting sur S&P 500 actuel inclut uniquement les survivants historiques, surestimant les performances. Mitigation : dataset point-in-time (CRSP-like).
- Data quality — les feeds SEC EDGAR et FRED sont gratuits mais bruités. Pipeline de validation + flags qualité avant scoring.
- Reproductibilité — LLMs non-déterministes.
temperature=0+ seeds + logging des raw responses pour audit.
Apprentissages
Le projet m'a appris plus sur l'orchestration distribuée et le tuning LLM en production que 2 ans de cours théoriques. Trois leçons qui s'exportent bien :
- La séparation des préoccupations bat l'intelligence monolithique. 12 agents simples + 1 orchestrateur produisent un meilleur signal qu'un seul LLM "générique" — et c'est bien plus débuggable.
- Le méta-apprentissage sur poids d'ensemble est sous-exploité dans l'industrie. Beaucoup d'équipes utilisent des ensembles avec des poids figés — on laisse beaucoup de valeur sur la table.
- Le coût LLM est une variable d'architecture. Mélanger plusieurs modèles selon la tâche (Haiku pour le scoring rapide, Opus pour la synthèse) divise le coût par 4 sans perte de qualité perçue.